voidvPrintString( constchar *pcString ) { /* Write the string to stdout, using a critical section as a crude method of mutual exclusion. */ taskENTER_CRITICAL(); { printf( "%s", pcString ); fflush( stdout ); } taskEXIT_CRITICAL(); }
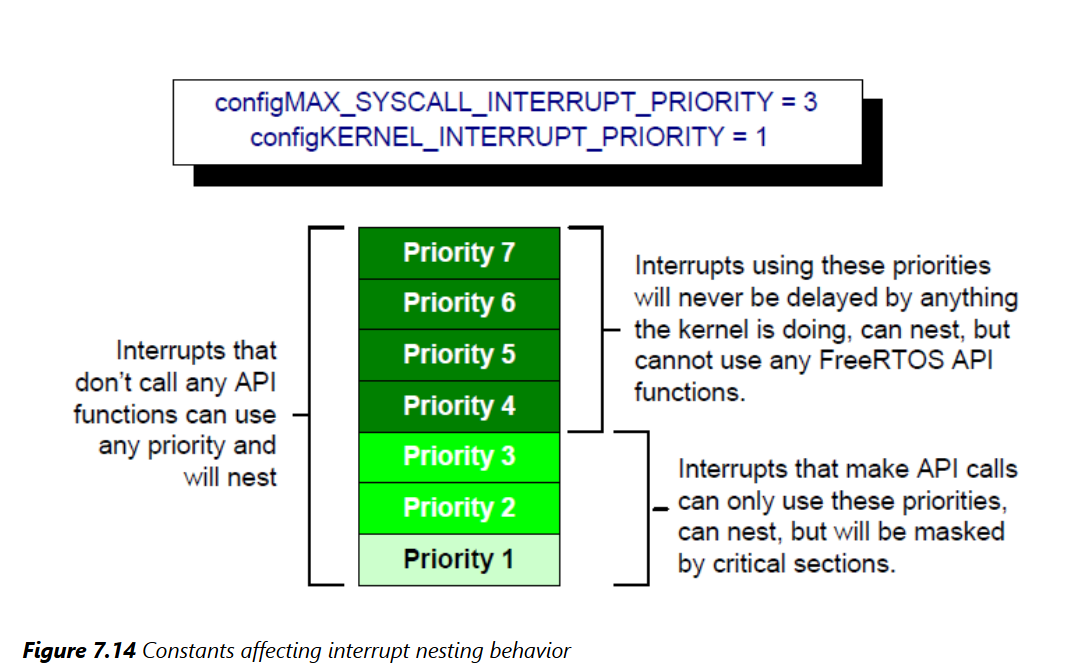
voidvAnInterruptServiceRoutine( void )//中断安全版本 { /* Declare a variable in which the return value from taskENTER_CRITICAL_FROM_ISR() will be saved. */ UBaseType_t uxSavedInterruptStatus; /* This part of the ISR can be interrupted by any higher priority interrupt. */ /* Use taskENTER_CRITICAL_FROM_ISR() to protect a region of this ISR. Save the value returned from taskENTER_CRITICAL_FROM_ISR() so it can be passed into the matching call to taskEXIT_CRITICAL_FROM_ISR(). */ uxSavedInterruptStatus = taskENTER_CRITICAL_FROM_ISR(); /* This part of the ISR is between the call to taskENTER_CRITICAL_FROM_ISR() and taskEXIT_CRITICAL_FROM_ISR(), so can only be interrupted by interrupts that have a priority above that set by the configMAX_SYSCALL_INTERRUPT_PRIORITY constant. */ /* Exit the critical section again by calling taskEXIT_CRITICAL_FROM_ISR(), passing in the value returned by the matching call to taskENTER_CRITICAL_FROM_ISR(). */ taskEXIT_CRITICAL_FROM_ISR( uxSavedInterruptStatus ); /* This part of the ISR can be interrupted by any higher priority interrupt. */ }
但是缺点也很明显, 临界区里的代码屏蔽了所有优先级相同或更低的中断
可能导致必要的中断无法执行
所以要求临界区要尽量的短, 上面这个例子明显不符合这个要求
第二种方法是通过暂停调度器
通过 vTaskSuspendAll()和xTaskResumeAll()
执行完vTaskSuspendAll()会暂停调度器的执行, 但是中断不受影响
调度器暂停了就不会有更高优先级的任务来抢占了
这个操作是可以嵌套的
内核会记录嵌套深度, 只有嵌套深度归0时, 才会恢复调度器
缺点就是终端仍有可能带来干扰, 同时恢复调度器通常是一个较为耗费时间的过程
示例:
1 2 3 4 5 6 7 8 9 10 11
voidvPrintString( constchar *pcString ) { /* Write the string to stdout, suspending the scheduler as a method of mutual exclusion. */ vTaskSuspendScheduler(); { printf( "%s", pcString ); fflush( stdout ); } xTaskResumeScheduler(); }
staticvoidprvNewPrintString( constchar *pcString ) { /* The mutex is created before the scheduler is started, so already exists by the time this task executes. Attempt to take the mutex, blocking indefinitely to wait for the mutex if it is not available straight away. The call to xSemaphoreTake() will only return when the mutex has been successfully obtained, so there is no need to check the function return value. If any other delay period was used then the code must check that xSemaphoreTake() returns pdTRUE before accessing the shared resource (which in this case is standard out). As noted earlier in this book, indefinite time outs are not recommended for production code. */ xSemaphoreTake( xMutex, portMAX_DELAY ); { /* The following line will only execute once the mutex has been successfully obtained. Standard out can be accessed freely now as only one task can have the mutex at any one time. */ printf( "%s", pcString ); fflush( stdout ); /* The mutex MUST be given back! */ } xSemaphoreGive( xMutex ); }
/* Recursive mutexes are variables of type SemaphoreHandle_t. */ SemaphoreHandle_t xRecursiveMutex; /* The implementation of a task that creates and uses a recursive mutex. */ voidvTaskFunction( void *pvParameters ) { const TickType_t xMaxBlock20ms = pdMS_TO_TICKS( 20 ); /* Before a recursive mutex is used it must be explicitly created. */ xRecursiveMutex = xSemaphoreCreateRecursiveMutex(); /* Check the semaphore was created successfully. configASSERT() is described in section 11.2. */ configASSERT( xRecursiveMutex ); /* As per most tasks, this task is implemented as an infinite loop. */ for( ;; ) { /* ... */ /* Take the recursive mutex. */ if( xSemaphoreTakeRecursive( xRecursiveMutex, xMaxBlock20ms ) == pdPASS ) { /* The recursive mutex was successfully obtained. The task can now access the resource the mutex is protecting. At this point the recursive call count (which is the number of nested calls to xSemaphoreTakeRecursive()) is 1, as the recursive mutex has only been taken once. */ /* While it already holds the recursive mutex, the task takes the mutex again. In a real application, this is only likely to occur inside a sub-function called by this task, as there is no practical reason to knowingly take the same mutex more than once. The calling task is already the mutex holder, so the second call to xSemaphoreTakeRecursive() does nothing more than increment the recursive call count to 2. */ xSemaphoreTakeRecursive( xRecursiveMutex, xMaxBlock20ms ); /* ... */ /* The task returns the mutex after it has finished accessing the resource the mutex is protecting. At this point the recursive call count is 2, so the first call to xSemaphoreGiveRecursive() does not return the mutex. Instead, it simply decrements the recursive call count back to 1. */ xSemaphoreGiveRecursive( xRecursiveMutex ); /* The next call to xSemaphoreGiveRecursive() decrements the recursive call count to 0, so this time the recursive mutex is returned. */ xSemaphoreGiveRecursive( xRecursiveMutex ); /* Now one call to xSemaphoreGiveRecursive() has been executed for every proceeding call to xSemaphoreTakeRecursive(), so the task is no longer the mutex holder. */ } } }
相同优先级任务使用互斥锁 处理时间不均问题
情景:
任务A,B两个相同优先级任务, 两个任务都来自同一个模板, 该模板如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
/* The implementation of a task that uses a mutex in a tight loop. The task creates a text string in a local buffer, then writes the string to a display. Access to the display is protected by a mutex. */ voidvATask( void *pvParameter ) { extern SemaphoreHandle_t xMutex; char cTextBuffer[ 128 ]; for( ;; ) { /* Generate the text string – this is a fast operation. */ vGenerateTextInALocalBuffer( cTextBuffer ); //快操作 /* Obtain the mutex that is protecting access to the display. */ xSemaphoreTake( xMutex, portMAX_DELAY ); /* Write the generated text to the display–this is a slow operation. */ vCopyTextToFrameBuffer( cTextBuffer ); //慢操作 /* The text has been written to the display, so return the mutex. */ xSemaphoreGive( xMutex ); } }
voidvFunction( void *pvParameter ) { extern SemaphoreHandle_t xMutex; char cTextBuffer[ 128 ]; TickType_t xTimeAtWhichMutexWasTaken; for( ;; ) { /* Generate the text string – this is a fast operation. */ vGenerateTextInALocalBuffer( cTextBuffer ); /* Obtain the mutex that is protecting access to the display. */ xSemaphoreTake( xMutex, portMAX_DELAY ); /* Record the time at which the mutex was taken. */ xTimeAtWhichMutexWasTaken = xTaskGetTickCount(); /* Write the generated text to the display–this is a slow operation. */ vCopyTextToFrameBuffer( cTextBuffer ); /* The text has been written to the display, so return the mutex. */ xSemaphoreGive( xMutex ); /* If taskYIELD() was called on each iteration then this task would only ever remain in the Running state for a short period of time, and processing time would be wasted by rapidly switching between tasks. Therefore, only call taskYIELD() if the tick count changed while the mutex was held. */ if( xTaskGetTickCount() != xTimeAtWhichMutexWasTaken ) //如果结束时和获取互斥量时不位于同一时间片 { taskYIELD(); } } }
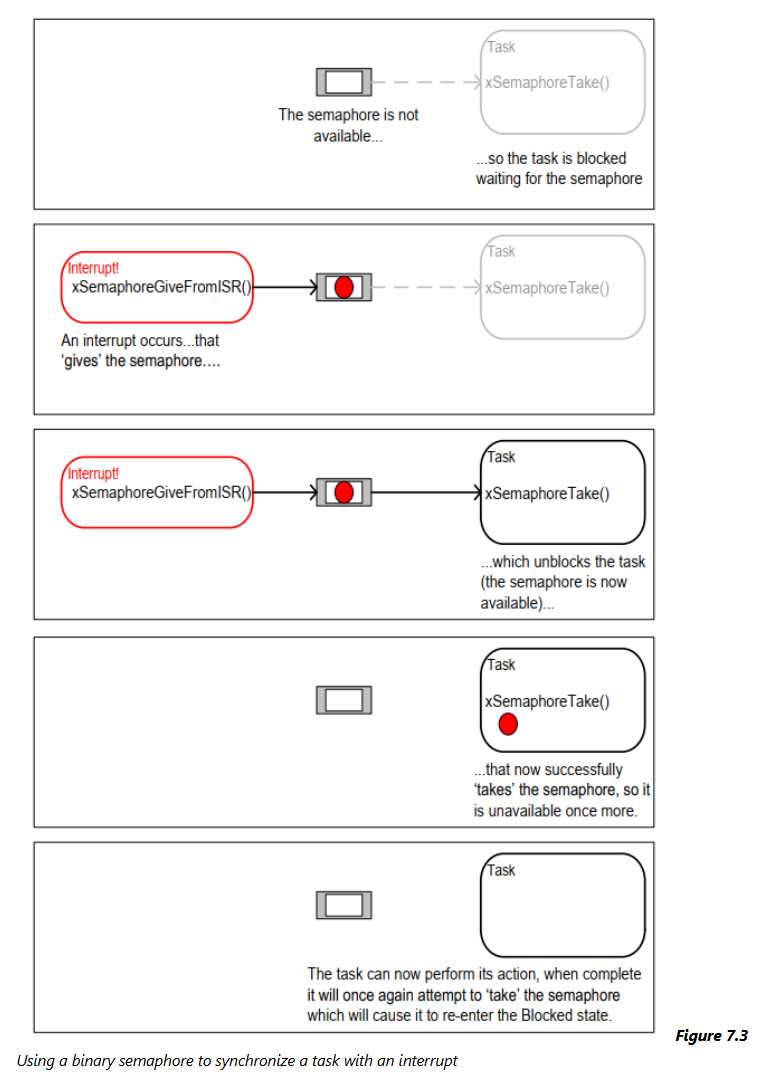
staticuint32_tulExampleInterruptHandler( void ) { BaseType_t xHigherPriorityTaskWoken; /* The xHigherPriorityTaskWoken parameter must be initialized to pdFALSE as it will get set to pdTRUE inside the interrupt safe API function if a context switch is required. */ xHigherPriorityTaskWoken = pdFALSE; /* 'Give' the semaphore to unblock the task, passing in the address of xHigherPriorityTaskWoken as the interrupt safe API function's pxHigherPriorityTaskWoken parameter. */ xSemaphoreGiveFromISR( xBinarySemaphore, &xHigherPriorityTaskWoken ); //二进制信号量 /* Pass the xHigherPriorityTaskWoken value into portYIELD_FROM_ISR(). If xHigherPriorityTaskWoken was set to pdTRUE inside xSemaphoreGiveFromISR() then calling portYIELD_FROM_ISR() will request a context switch. If xHigherPriorityTaskWoken is still pdFALSE then calling portYIELD_FROM_ISR() will have no effect. Unlike most FreeRTOS ports, the Windows port requires the ISR to return a value - the return statement is inside the Windows version of portYIELD_FROM_ISR(). */ portYIELD_FROM_ISR( xHigherPriorityTaskWoken ); }
intmain( void ) { /* * Variables declared here may no longer exist after starting the FreeRTOS * scheduler. Do not attempt to access variables declared on the stack used * by main() from tasks. */ /* * Create one of the two tasks. Note that a real application should check * the return value of the xTaskCreate() call to ensure the task was * created successfully. */ xTaskCreate( vTask1, /* Pointer to the function that implements the task.*/ "Task 1",/* Text name for the task. */ 1000, /* Stack depth in words. */ NULL, /* This example does not use the task parameter. */ 1, /* This task will run at priority 1. */ NULL ); /* This example does not use the task handle. */ /* Create the other task in exactly the same way and at the same priority.*/ xTaskCreate( vTask2, "Task 2", 1000, NULL, 1, NULL ); /* Start the scheduler so the tasks start executing. */ vTaskStartScheduler(); /* * If all is well main() will not reach here because the scheduler will now * be running the created tasks. If main() does reach here then there was * not enough heap memory to create either the idle or timer tasks * (described later in this book). Chapter 3 provides more information on * heap memory management. */ for( ;; ); }
voidvTask1( void * pvParameters ) { constchar *pcTaskName = "Task 1 is running\r\n"; volatileunsignedlong ul; /* volatile to ensure ul is not optimized away. */ /* * If this task code is executing then the scheduler must already have * been started. Create the other task before entering the infinite loop. */ xTaskCreate( vTask2, "Task 2", 1000, NULL, 1, NULL ); for( ;; ) { /* Print out the name of this task. */ vPrintLine( pcTaskName ); /* Delay for a period. */ for( ul = 0; ul < mainDELAY_LOOP_COUNT; ul++ ) { /* * This loop is just a very crude delay implementation. There is * nothing to do in here. Later examples will replace this crude * loop with a proper delay/sleep function. */ } } }
voidvTaskFunction( void * pvParameters ) { char *pcTaskName; volatileunsignedlong ul; /* volatile to ensure ul is not optimized away. */ /* * The string to print out is passed in via the parameter. Cast this to a * character pointer. */ pcTaskName = ( char * ) pvParameters; /* As per most tasks, this task is implemented in an infinite loop. */ for( ;; ) { /* Print out the name of this task. */ vPrintLine( pcTaskName ); /* Delay for a period. */ for( ul = 0; ul < mainDELAY_LOOP_COUNT; ul++ ) { /* * This loop is just a very crude delay implementation. There is * nothing to do in here. Later exercises will replace this crude * loop with a proper delay/sleep function. */ } } }
/* * Define the strings that will be passed in as the task parameters. These are * defined const and not on the stack used by main() to ensure they remain * valid when the tasks are executing. */ staticconstchar * pcTextForTask1 = "Task 1 is running"; staticconstchar * pcTextForTask2 = "Task 2 is running"; intmain( void ) { /* * Variables declared here may no longer exist after starting the FreeRTOS * scheduler. Do not attempt to access variables declared on the stack used * by main() from tasks. */ /* Create one of the two tasks. */ xTaskCreate( vTaskFunction, /* Pointer to the function that implements the task. */ "Task 1", /* Text name for the task. This is to facilitate debugging only. */ 1000, /* Stack depth - small microcontrollers will use much less stack than this.*/ ( void * ) pcTextForTask1, /* Pass the text to be printed into the task using the task parameter.*/ 1, /* This task will run at priority 1.*/ NULL ); /* The task handle is not used in this example. */ /* * Create the other task in exactly the same way. Note this time that * multiple tasks are being created from the SAME task implementation * (vTaskFunction). Only the value passed in the parameter is different. * Two instances of the same task definition are being created. */ xTaskCreate( vTaskFunction, "Task 2", 1000, ( void * ) pcTextForTask2, 1, NULL ); /* Start the scheduler so the tasks start executing. */ vTaskStartScheduler(); /* * If all is well main() will not reach here because the scheduler will * now be running the created tasks. If main() does reach here then there * was not enough heap memory to create either the idle or timer tasks * (described later in this book). Chapter 3 provides more information on * heap memory management. */ for( ;; ) { } }
voidvTaskFunction( void * pvParameters ) { char * pcTaskName; const TickType_t xDelay250ms = pdMS_TO_TICKS( 250 ); /* * The string to print out is passed in via the parameter. Cast this to a * character pointer. */ pcTaskName = ( char * ) pvParameters; /* As per most tasks, this task is implemented in an infinite loop. */ for( ;; ) { /* Print out the name of this task. */ vPrintLine( pcTaskName ); /* * Delay for a period. This time a call to vTaskDelay() is used which * places the task into the Blocked state until the delay period has * expired. The parameter takes a time specified in 'ticks', and the * pdMS_TO_TICKS() macro is used (where the xDelay250ms constant is * declared) to convert 250 milliseconds into an equivalent time in * ticks. */ vTaskDelay( xDelay250ms ); } }
voidvTaskFunction( void * pvParameters ) { char * pcTaskName; TickType_t xLastWakeTime; /* * The string to print out is passed in via the parameter. Cast this to a * character pointer. */ pcTaskName = ( char * ) pvParameters; /* * The xLastWakeTime variable needs to be initialized with the current tick * count. Note that this is the only time the variable is written to * explicitly. After this xLastWakeTime is automatically updated within * vTaskDelayUntil(). */ xLastWakeTime = xTaskGetTickCount(); /* As per most tasks, this task is implemented in an infinite loop. */ for( ;; ) { /* Print out the name of this task. */ vPrintLine( pcTaskName ); /* * This task should execute every 250 milliseconds exactly. As per * the vTaskDelay() function, time is measured in ticks, and the * pdMS_TO_TICKS() macro is used to convert milliseconds into ticks. * xLastWakeTime is automatically updated within vTaskDelayUntil(), so * is not explicitly updated by the task. */ vTaskDelayUntil( &xLastWakeTime, pdMS_TO_TICKS( 250 ) ); } }
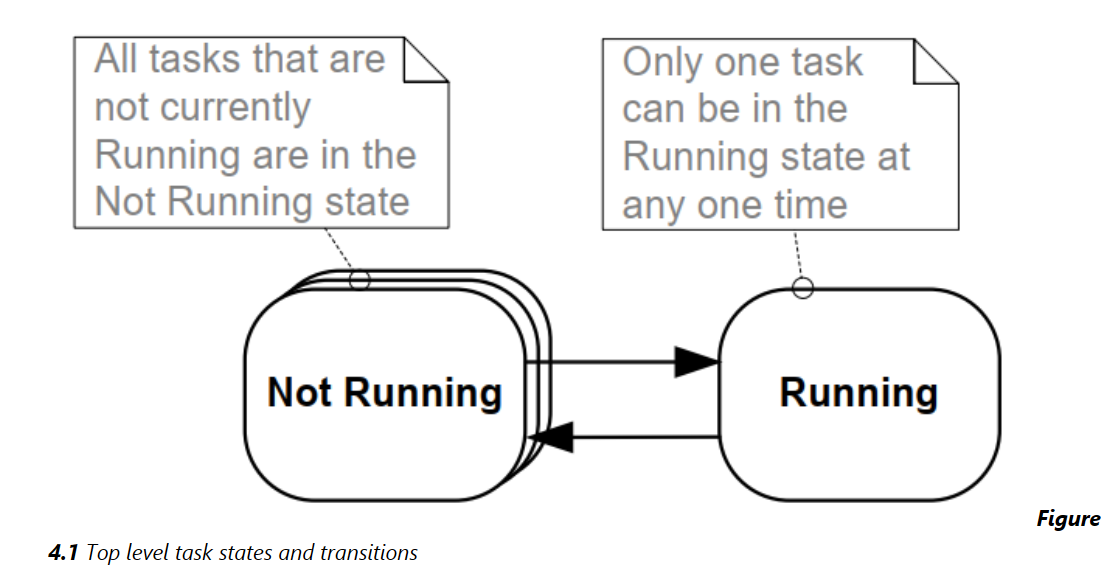
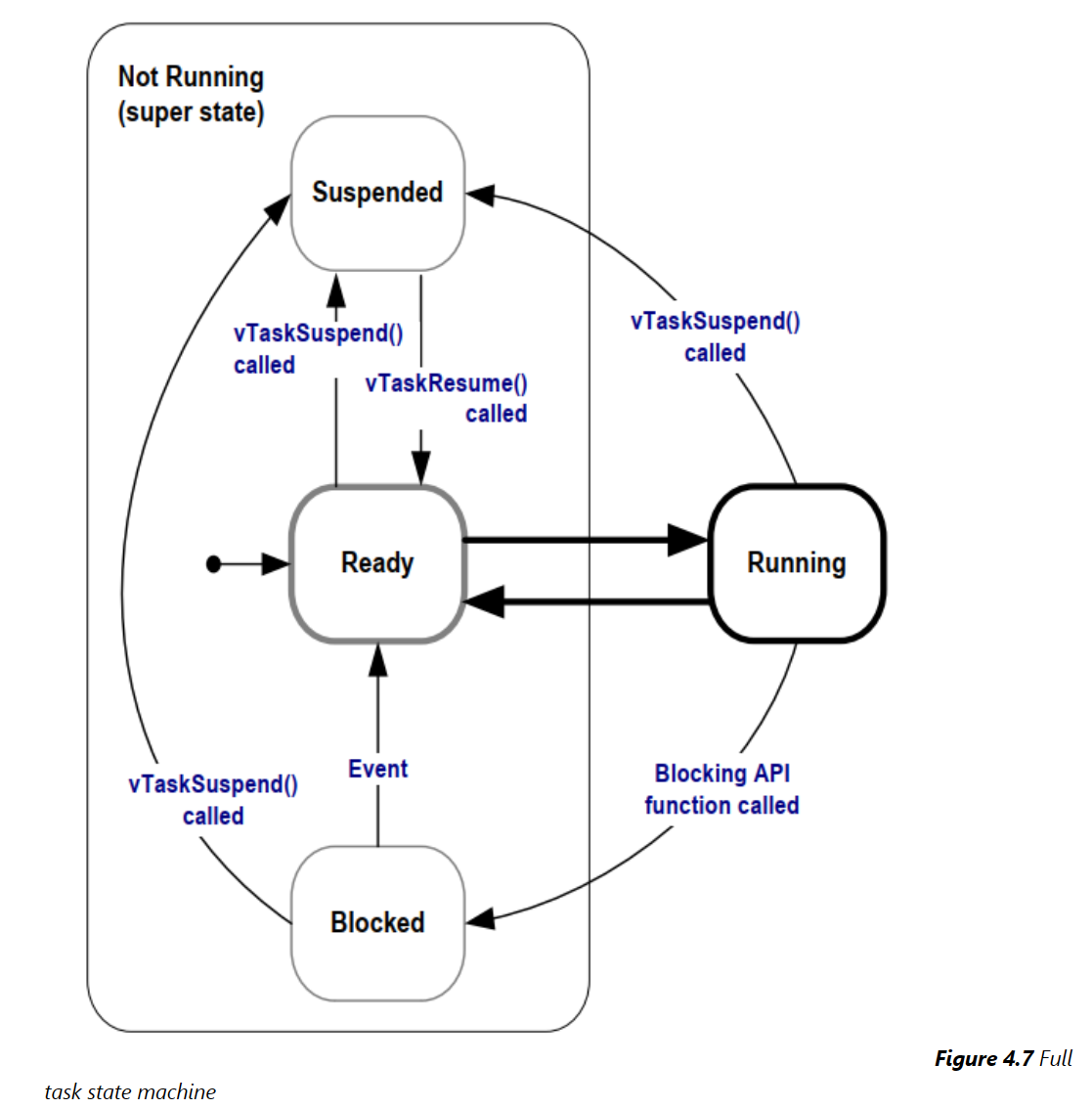
挂起态
处于挂起状态的任务不可用于调度程序。进入挂起状态的唯一方法是通过调用 vTaskSuspend() API 函数,而退出状态的唯一方法是调用 vTaskResume() 或 xTaskResumeFromISR() API 函数。大多数应用程序不使用挂起状态
至此, 总结出四种状态的状态转换图
删除(Delete)一个任务
vTaskDelete() API 函数删除任务。仅当 FreeRTOSConfig.h 中的 INCLUDE_vTaskDelete 设置为 1 时,vTaskDelete() API 函数才可用
注意:**以任何方式阻止空闲任务都可能导致没有任务可进入运行状态的情况。**如果应用程序任务使用 vTaskDelete() API 函数删除自身,则空闲任务挂钩必须始终在合理的时间段内返回到其调用者。这是因为空闲任务负责清理分配给删除自身的任务的内核资源。如果空闲任务永久保留在空闲挂钩函数中,则无法进行此清理
线程本地存储(TLS)允许应用程序开发人员在每个任务的任务控制块中存储任意数据。此功能最常用于存储通常由不可重入函数存储在全局变量中的数据。可重入函数是可以从多个线程安全运行而没有任何副作用的函数。当在没有线程本地存储的多线程环境中使用不可重入函数时,必须特别注意检查临界区内这些函数调用的带外结果。过度使用临界区会降低 RTOS 性能,因此线程本地存储通常优于使用临界区。到目前为止,线程本地存储最常见的用途是 C 标准库和 POSIX 系统使用的 ISO C 标准中使用的 errno 全局变量。 errno 全局用于为常见标准库函数(例如 strtof 和 strtol)提供扩展结果或错误代码
大多数嵌入式 libc 实现都提供 API 以确保不可重入函数可以在多线程环境中正常工作。 FreeRTOS 支持两个常用开源库的重入 API:newlib 和 picolibc。这些预构建的 C 运行时线程本地存储实现可以通过在其项目的 FreeRTOSConfig.h 文件中定义下面列出的相应宏来启用
应用程序开发人员可以通过在 FreeRTOSConfig.h 文件中定义以下宏来实现线程本地存储: 将 configUSE_C_RUNTIME_TLS_SUPPORT 定义为 1 以启用 C 运行时线程本地存储支持。将 configTLS_BLOCK_TYPE 定义为 c 类型,该类型应用于存储 C 运行时线程本地存储数据。将 configINIT_TLS_BLOCK 定义为初始化 C 运行时线程本地存储块时应运行的 C 代码。将 configSET_TLS_BLOCK 定义为切换新任务时应运行的 c 代码 将 configDEINIT_TLS_BLOCK 定义为在取消初始化 C 运行时线程本地存储块时应运行的 c 代码